Funktionen
Modellkonfiguration
Erfahren Sie, wie Sie KI-Modelle in der Canvas-Funktion konfigurieren und optimieren, um die Chatbot-Leistung zu verbessern.
Die Modellkonfiguration-Funktion in Canvas ermöglicht es Ihnen, das Verhalten Ihrer KI durch Anpassung wichtiger Parameter zu gestalten. Dies ermöglicht Ihnen, Antworten zu erstellen, die Ihrem gewünschten Ton, Ihrer Präzision und Länge entsprechen, um sicherzustellen, dass der Chatbot in jedem Szenario optimal funktioniert.
Wichtige Parameter in der Modellkonfiguration
1. Temperatur
Der Temperatur-Parameter steuert die Kreativität der Chatbot-Antworten:- Niedrigere Werte (00.3): Generieren präzise, faktenbasierte und deterministische Antworten.
- Höhere Werte (0.71.0): Produzieren kreative, vielfältige und offene Antworten.
- Kundensupport: Setzen Sie die Temperatur auf
0.2für faktische und konsistente Antworten. - Kreative Aufgaben: Setzen Sie die Temperatur auf
0.8für das Generieren innovativer Ideen oder Inhalte.
2. Max Tokens
Der Max Tokens-Parameter begrenzt die Länge der Chatbot-Antwort.- Ein höheres Token-Limit ermöglicht detaillierte Antworten.
- Ein niedrigeres Token-Limit gewährleistet prägnante und punktgenaue Antworten.
- Zusammenfassungen: Begrenzen Sie Tokens auf
100für kurze Zusammenfassungen. - Detaillierte Erklärungen: Erhöhen Sie das Limit auf
500für ausführliche Erklärungen.
3. Rewind-Level
Das Rewind-Level bestimmt, wie weit der Chatbot auf vorherige Knoten im Ablauf zurückgreifen kann:- Level 0: Kein Rewind, der Chatbot berücksichtigt nur den aktuellen Knoten.
- Level 13: Der Chatbot kann auf bis zu 3 vorherige Knoten für zusätzlichen Kontext zugreifen.
- Fehlerbehandlung: Setzen Sie das Rewind-Level auf
1, um fehlgeschlagene Aktionen erneut zu versuchen. - Komplexe Konversationen: Verwenden Sie Rewind-Levels von
23, um den Kontext über mehrere Knoten hinweg beizubehalten.
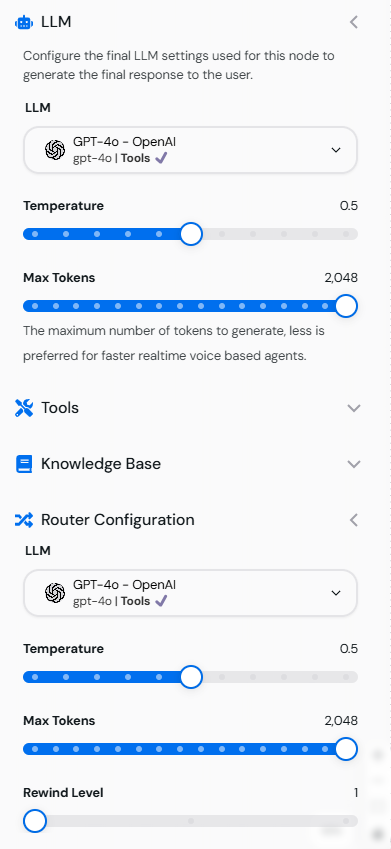
Modelle in den Knoteneinstellungen konfigurieren
- Öffnen Sie den LLM-Konfiguration-Tab in den Einstellungen eines Knotens.
-
Passen Sie die folgenden Parameter an:
- Temperatur: Schieben Sie den Regler auf das gewünschte Level.
- Max Tokens: Setzen Sie ein spezifisches Token-Limit für Antworten.
- Rewind-Level: Wählen Sie das Rewind-Level für die Verwaltung des Konversationskontexts.
Bild, das den LLM-Konfiguration-Tab mit Temperatur-, Max-Tokens- und Rewind-Level-Einstellungen zeigt.
Beispielkonfigurationen
1. Präzise und faktische Antworten
- Temperatur:
0.1 - Max Tokens:
200 - Rewind-Level:
0
2. Kreative und offene Antworten
- Temperatur:
0.9 - Max Tokens:
500 - Rewind-Level:
2
3. Kontextuelle Konversationen
- Temperatur:
0.3 - Max Tokens:
300 - Rewind-Level:
3
Modelleinstellungen testen
- Verwenden Sie das Test-Werkzeug im Canvas-Arbeitsbereich, um Antworten zu simulieren.
- Geben Sie Anfragen ein, die Ihrem beabsichtigten Anwendungsfall entsprechen.
- Passen Sie die Parameter nach Bedarf für bessere Ergebnisse an.
Best Practices für die Modellkonfiguration
- Parameter an Anwendungsfälle anpassen: Passen Sie Temperatur und Max Tokens an die spezifischen Anforderungen Ihres Chatbots an.
- Iterativ testen: Führen Sie mehrere Tests durch, um die Einstellungen fein abzustimmen.
- Kreativität und Präzision ausbalancieren: Verwenden Sie mittlere Temperaturwerte (
0.40.6) für Antworten, die sowohl kreativ als auch genau sind. - Rewind-Levels nutzen: Aktivieren Sie Kontextbeibehaltung für bessere Benutzerinteraktionen.
Beispiel-Ablauf mit konfigurierten Modellen
Szenario: Ein Mehrzweck-Chatbot:- Startknoten: Begrüsst den Benutzer mit einem kreativen Ton (Temperatur
0.7). - FAQ-Knoten: Liefert präzise Antworten mit einem faktischen Ton (Temperatur
0.2). - Feedback-Knoten: Fragt nach Benutzer-Feedback mit einem ansprechenden Ton (Temperatur
0.5).