Daten hinzufügen
URL hinzufügen
URL-Scraping ist ein leistungsstarkes Werkzeug, um automatisch Daten von Websites zu extrahieren und Ihre Wissensdatenbank zu befüllen.
- Extrahiert automatisch Daten von Websites.
- Gewährleistet relevante und aktuelle Inhalte.
1
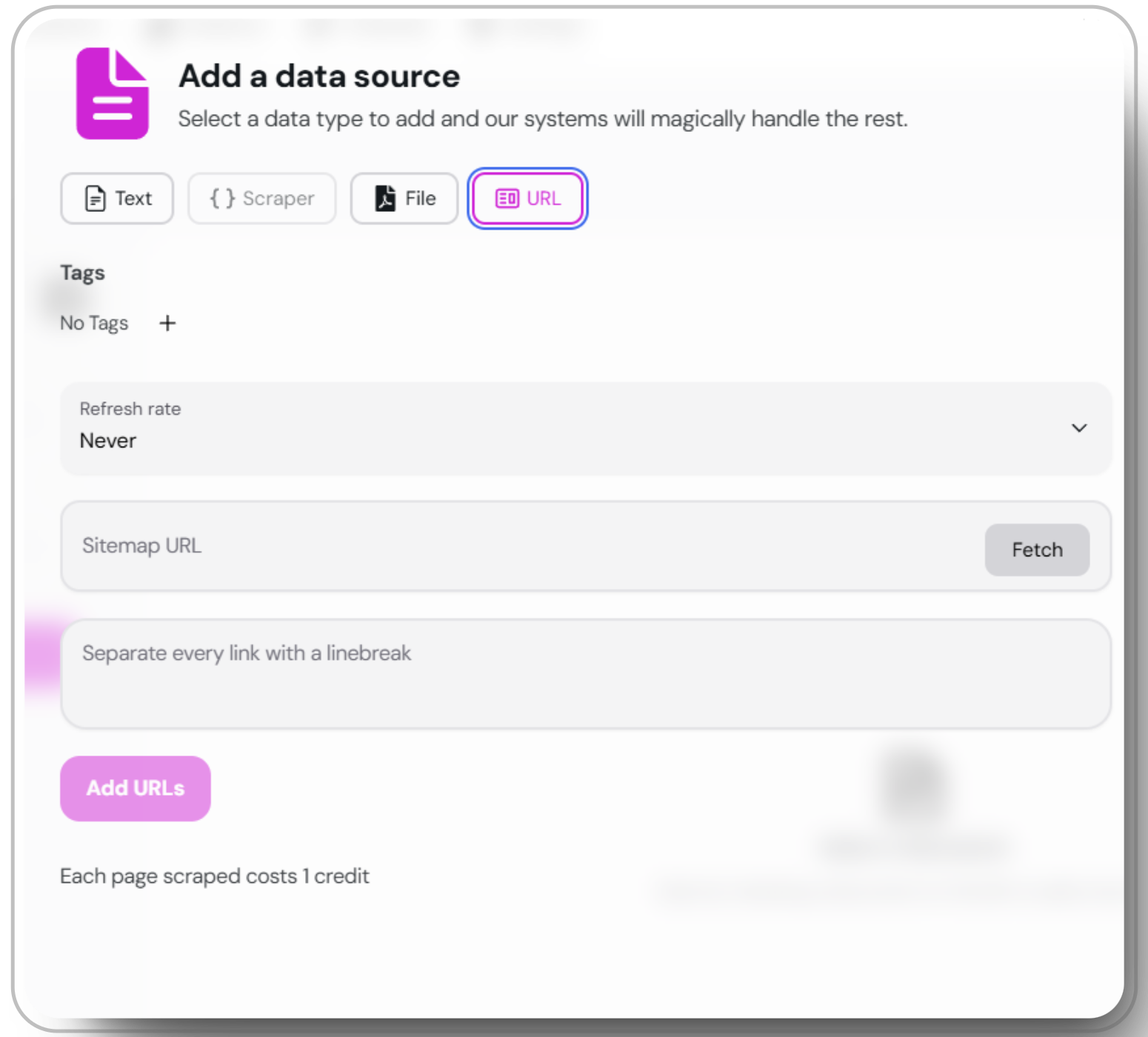
Wählen Sie 'URL' im Fenster 'Datenquelle hinzufügen'
Öffnen Sie das Fenster Datenquelle hinzufügen und wählen Sie die Option “URL”.
2
Geben Sie die URL oder Sitemap ein
Geben Sie die URL oder Sitemap ein, die Sie scrapen möchten. Drücken Sie
etch, um die Sitemap aus der XML-Datei abzurufen und zu überprüfen.
3
Scrapen Sie die Daten
Sobald die URLs abgerufen wurden, scrapen Sie die Daten und speichern Sie diese als einzelne Dokumente. Scrollen Sie durch und entfernen Sie unerwünschte Informationen, um die Relevanz sicherzustellen.
Die Verwendung des URL-Scrapers verbraucht X Credits pro Seite. Bitte stellen Sie sicher, dass Ihr Konto über ausreichend Credits verfügt.
Überprüfen Sie die extrahierten Daten regelmässig auf Relevanz und Genauigkeit, um eine hochwertige Wissensdatenbank zu gewährleisten.